20211123 화요일 오후-데이터베이스-SQL 기초-김동원쌤
Introduction to SQL
이번 SQL과정은 13장까지만. 총 11개장. 2개장은 스킵. 14장부터는 고급기능.
이 과정에서 배운 것을 수료할 때까지 써먹을 것이다.
교재는 Oracle9i Introduction to Oracle9i SQL (한글판)
SQL은 관계형 데이터베이스를 위한 표준어. 다른 데이터베이스에서도 공통으로 사용되는 부분이 많다.
@ Page 23.
테이블은 데이터를 저장되는 곳.
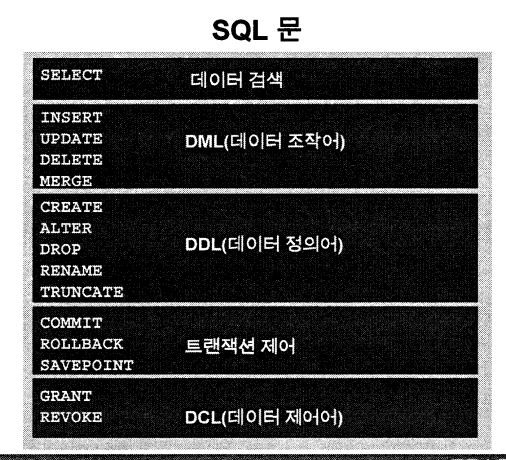
DML(Data Manipulation Language) 데이터 조작어. 데이터를 조회하거나 검색할 때.
DDL(Data Definition Language) 데이터 정의어. 데이터 구조를 가지고 있는 걸 정의하고 생성할 때.
TCL(Transaction Control Language) 트랜잭션 제어 언어. DML로 나온 결과를 트랜잭션(작업단위)별로 제어할 때.
DCL(Data Control Language) 데이터 제어어. 데이터베이스에 접근, 권한, 회수할 때.
@ 강의 순서 및 주의 사항
SELECT 가지고 5일을 한다. 문법은 6줄이다. 데이터를 분석할때 쓰는 명령어. 왜 이걸 사용해야 하는지?
예제를 많이 풀것이다. DB 끝나고 시험본다. NCS 시험범위는 전체 범위.
풀네임을 알고 쓰자(의미). VARCHAR (Variable Character) 풀네임으로 불러라.
DESC 구조나 내림차순인데 어디에서 사용되냐에 따라 의미가 달라진다.
@ 첫번째 명령어.
SELECT - 검색할 때 사용하는 명령어.
- 데이터베이스의 저장된 데이터는 데이터 무결성과 정확성.
- 데이터를 가공해서 얻어낸 정보가 필요하냐? 바로 회사의 수익구조의 향상을 위해서....
- 무결성의 중요성: 정확하지 않은 데이터로 인해서 문제가 발생할 수 있기 때문에.
어딘가에 활용하기 위해 SELECT라는 명령문을 활용한다.


- 테이블은 여러개의 컬럼들로 구성. SELECTION은 모든 컬럼의 데이터를 보고자 할 때 사용.
- PROJECTION은 내가 원하는 특정 컬럼의 데이터를 검색할 때 사용.
- JOIN 은 다수의 테이블에서 데이터를 검색할 때 사용한다.

select, from 반드시 두개를 동시에 사용한다.
select list 절 -> 보고자 하는 데이터를 소유한 컬럼이름. => 여기에 명시된 컬럼의 데이타 결과 출력.
select list 에 어떤 컬럼 이름을 적을 것이냐가 가장 첫번째로 해야 할 일.
select column 은 출력과 관련이 있다. 결과 출력.

select column_name(출력)
from table_name 은 테이블이 소유한 컬럼을 선택하는 명령어. 이게 가장 기초 문법이다.
SQL은 비절차적 언어라고 한다.

라면을 먹는다면 라면을 찾으러 가야한다. 그래서 table_name이 시작이다. kk, dd 결과값을 얻기 위해서는 일단 select list 절인 column_name인 Last_name에서 검색 해라. 이게 기본 문법이다.

Tip. 결과값을 직역아닌 의역할 줄 알아야 한다.
@ *(Asterisk, 아스터리스크)는 모든 컬럼의 모든 데이터를 검색하시오. 전체 데이터를 보고 싶을때.
테이블의 데이터 관리는 기본이 행이다. 행단위로 관리. 이 행안에 저장되어 있는 데이터는 서로가 서로를 나타내는 데이터이기 때문이다.
아래는 우리 회사는 10번부서부터 270번까지 존재.. 27개의 행이 존재. 부서의 갯수가 27개이다 라는 뜻.

각각이 뭘 의미하는지를 파악해야 한다. SELECT의 명령어는 ....~
컬럼의 이름을 직접 입력할 수도 있다. * 아스터리스크 안쓰고. 이런 식으로 말이지.

맨 위에 컬럼 이름. 이 데이터가 무슨 데이타인지 알 길이 없기 때문에 select를 쓰면 항상 상단에 이름이 나온다.
이걸 열머리글 (Column heading) - 결과로 출력이 되었을때 떨어지는 열 이름을 열머리글이라고 한다.
테이블에 저장되어 있는 컬럼 이름은 이미 회사에서 지정해 놓은 것이다. 네이밍 규칙을 철저하게 지키는 것이다. 하나의 보고서 개념이다. 어떤 결과를 토대로 열머리글이 달라질 수 있다.

보고서의 특성에 따라서 보고서의 제목(테이블 이름)을 변경해야 한다.
그리고 출력이 되는 결과는

ed 값을 수정하면 컬럼의 순서가 바뀐다. 이말인 즉슨, 컬럼을 쓰는 순서에 따라 달라진다. select list 절에 어떠한 컬럼을 적을 것이냐? 를 결정해야 한다.

TIP. SQL buffer에는 하나의 명령어만 저장이 되어 있다. 만약에 에러가 나면 ed를 열어서 수정한 후 다시 저장하고 run해라.

그 데이터가 소유한 테이블을 명시 해야 한다. 그 테이블 명시는 from절에 명시해라.
질문. 만약에 보스가 무언가 일을 시켰는데 아무런 정보가 없을 때는 어떡하지?
DESC tabs를 보면 전체가 테이블이다. 테이블 리스트를 볼 수 있다. 아래 처럼 말이지.
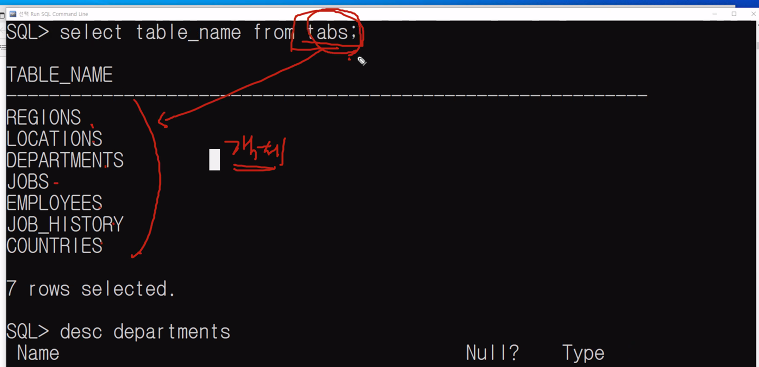
desc 명령어로 컬럼의 구조를 볼 수 있다.
내 생각에는 테이블과 컬럼을 몰라도 tabs와 desc를 쳐보면 된다.
프로잭션 기능은 select 절에 나열된 것만 본다. 이렇게...

우리 회사에 존재하는 부서와 위치를 알아보세요.

부서와 위치가 서로 관련있는지를 알고 있는게 중요.
select와 projection 은 select list
@ 문제1.

select list를 먼저 결정하자.
select last_name, department_id from employees;



지금 10개씩 나누어 떨어지는 이유는 보기 좋으라고 해놨다. 편집 명령어가 30~40개 된다. 몰라도 된다. 다 알게 되면 별도 만들고, 뿡뿡이도 만들수 있다. 그걸로.
select column_name from table_name 이게 다다. 대소문자 구분 안한다. 하지만 우리는 해야 한다. 성능향상을 위해.

@ 왜 대소문자를 구분해야 하냐면, 이걸 구분하면 select검색속도가 향상된다. 데이터베이스도 컴파일같은 작업을 하는데 이걸 파싱(parsing)이라고 한다. 파싱은 3단계로 이루어져 있다.
- 검증 작업.
- 실행계획. 테이블로 부터 데이터를 가져오는 방법. 가장빠른방법을 선택
- 실행.
select name from emp; 파싱전에 하는 작업... 이걸 데이터 딕셔너리를 검색한다고 한다. 이게 뇌하고 비슷하다.
하나의 물리적인 데이터를 메타데이터라고 표현하는데 이걸 데이터 딕셔너리라고 한다. 방금 전에 실행시켰던 parse 정보하고 문장 텍스트도 저장되어 있다. 데이터 딕셔너리는 캐시하고 약간 다르다. 좀 더 확장된 개념. 큐라는 자료 구조형태로 만들어져 있다. 그런데 대소문자를 구조가 다르면 명령어는 같더라도 아스키 코드 값이 다르기 때문에 다시 파싱을 한다. 그러면 데이터 딕셔너리를 쓸 수 없어서 속도가 떨어진다. 그래서 불문율처럼 규약(대소문자 구분, 등등)을 만들어 놓는다. 속도 향샹을 위해...

그래서 항상 자신만의 코드 방식을 정해 놔라. 일반적인 규약은 명령어는 SELECT 대문자로 쓰고 컬럼이름은 소문자로 쓴다. 우리만의 코드 규약...
- 가독성이 좋은게 성능도 좋다. 그래서 각각 다른 라인에다 쓰는 걸 추천한다.

- 열머리글들은 항상 대문자로 출력이 이루어진다. 대문자로 정보가 저장되어 있다. 데이터 딕셔너리도 마찬가지.
@ 문제2. 사원의 번호와 그 사원이 받는 월 급여를 출력하시오.

@ 문제3. 사원의 번호와 그 사원이 받는 연봉을 출력하시오.


연봉을 구하고 싶으면 select list 절에 있어야 한다. select list절에서 산술연산을 할 수있다. select 명령어는 데이터의 구조를 바꾸는 명령어가 아니기 때문에 테이블의 데이터는 변하지 않는다.
산술연산은 컬럼 + 상수, 컬럼+컬럼 연산도 가능하다.
select last_name+100 from employees; 에라다.( 쌈마이웨이!)

select hire_date*12 from employees; 에러다.

select hire_date, hire_date+7, hire_date-7 from employees; 에러다.
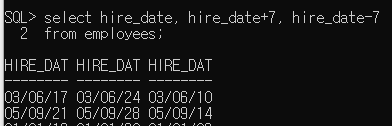
산술연산은 숫자 되고, 문자 안되고, 날짜 중에 일수 연산(+-)가능, 단 */ 연산은 불가능. 실질적 테이블에는 날짜값이 숫자로 저장되어 있다. 그래서 가능하다. */는 의미가 없어서 불가능하다.

연산자 우선 순위...

@ 문제 4. 사원의 번호와 연봉을 구하시오. 단 보너스를 받는 사원은 보너스를 곱한 값을 출력하시오.
select employee_id, salary*12*commission_pct from employees;
null에 대한 산술연산은 결과가 무조건 null 이다.

select employee_id, salary*12*NVL(commission_pct, 1) from employees;
이 말의 의미는 NVL(Non Value Language)라는 함수를 사용한다. commission_pct에 null 값을 1로 변경해라.
select employee_id, salary*12*NVL(commission_pct, 0) from employees;
이 말의 의미는 0으로 대체한다.
정리하자면,
null에 대한 산술연산은 null이다. 그래서 NVL이라는 함수를 사용한다.

그런데 가독성이 떨어지니까 이렇게 바꾼다.
select employee_id, salary*12..... as annsal
@ 열 별칭(알리아스):
열머리글의 이름을 변경합니다. 열 별칭 정의(alias). Alias 기능은 컬럼 다음에 위치한다. 한 개의 컬럼당 한개의 알리아스만 사용할 수 있다.


알리아스를 주는 방법이 두가지다. as를 쓰거나 블랭크를 쓰거나.
단일문장을 주고자 할 때, 대문자 출력이 된다. 공백이 나타면 다음에 나타나는 이름은 컬럼 이름으로 인식해서 뒤지기 시작한다. 그러면 속도가 느려진다.

둘 중에 sal*12 가 속도가 더 빠르다. 왜냐하면 sal은 컬럼이름이니까 먼저 인식하고 그다음에 상수가 인식이 된다. 이게 더 빠르다. 상수가 앞에 나오면 컴퓨터가 이 상수에 대해 검색한다. 그래서 속도가 더 느리다.
알리아스는 컬럼의 이름이 바뀌는 게 아니라 이 결과값을 출력할 때만 바뀌어서 열머리글을 출력한다.

알리아스를 주는 방법이 세가지다. as, 블랭크, 쌍따옴표. 쌍따옴표는 복수문장을 사용할 때 쓰인다. 쓰여진 형식 그대로 출력한다. 대소문자 구분하고 싶을때 사용.

성능관련 내용. select last_name as "Name", ..... 이런 식으로 알리아스를 중복해서 쓰지 말아라. 속도 떨어진다.
쓸려면 이렇게 써라.

쿼리가 만건 오만건 이상일 때 성능의 차이가 난다. 1초, 2초.
@ 성능을 떨어뜨리는 이유 두가지.
- 정렬.
- 조인.
튜닝은 문제가 발생하지 않도록 성능을 개선하는 것이다. 그래서 데이터베이스 튜닝이 중요하다.
@ 연결 연산자
||
SELECT 문장에서 나머지를 제외하고 나열된 숫자, 문자, 날짜값을 리터럴 문자열이라고 한다.

문자와 날짜값을 표기하고자 할 때는 작은따옴표를 꼬옥 붙여야 한다.
허벌나게 중요허다... 이거 안붙이면 컬럼 이름으로 인식해버리기 때문이다. 이게 리터럴 문자열이라는 것을 알려주기 위해서다.

여기까지....
지금까지 배운것은,
select * column alias ---> list 보고자 하는 데이터를 소유한 컬럼 이름 => 명시된 컬럼 데이터 결과 출력. 중요..
from
* 모든 것을 다 보고 싶을때. 특정컬럼 명시하고자 할 때, 등등.
이게 오늘 배운 것 모두 정리한 것:
